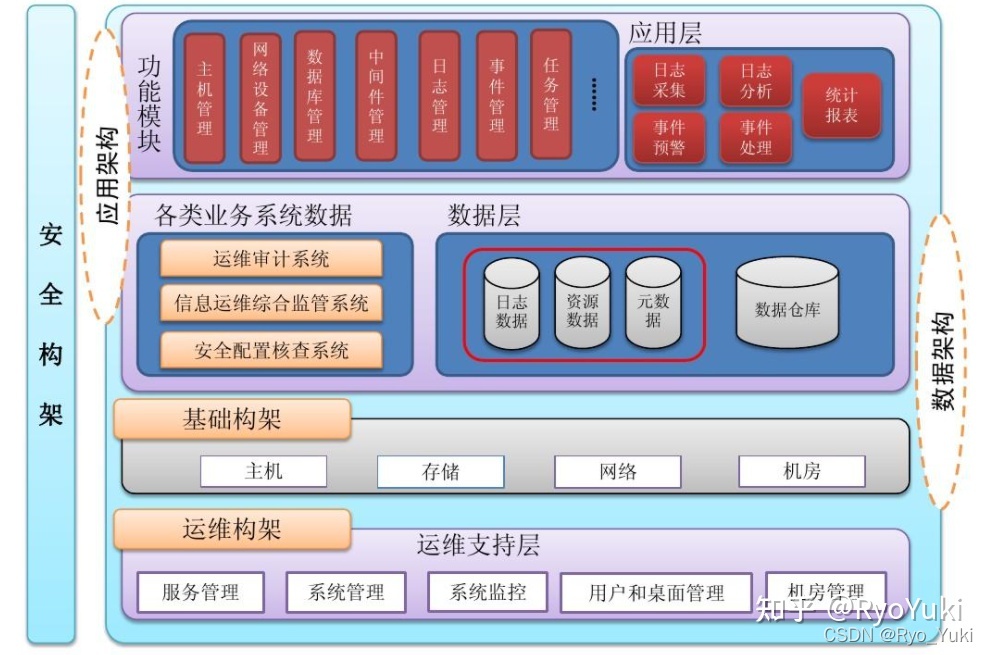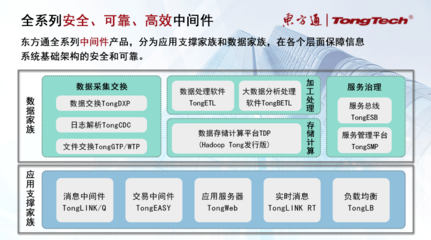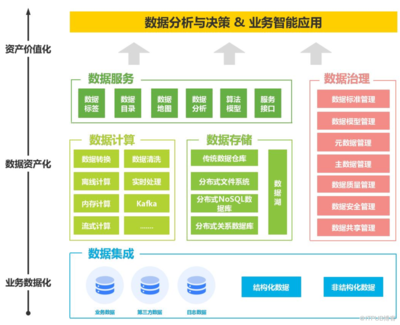
随着企业数据量的爆炸式增长和数据源的日益多样化,传统的数据管理与集成方式已难以满足现代业务对实时性、灵活性和安全性的需求。在此背景下,“数据编织”作为一种创新的数据管理和集成架构,正迅速成为企业构建智能化数据处理与存储支持服务的核心框架。
一、数据编织的定义与核心理念
数据编织是一种集成的数据架构,它通过结合元数据、知识图谱、人工智能和自动化技术,为跨平台、跨环境的数据提供统一的访问、集成、管理和治理能力。其核心理念在于构建一个智能的、自适应的“数据网络”,使得数据能够像织物一样被灵活地编织在一起,无论数据存储在何处、格式如何,都能被高效地发现、理解和使用。
与传统的点对点集成或数据湖/仓库模式不同,数据编织强调以业务为中心,通过主动元数据驱动,实现数据的上下文感知和智能推荐,从而降低数据管理的复杂性,提升数据利用效率。
二、数据编织如何支持数据处理与存储服务
1. 统一的数据访问与集成层
数据编织在底层异构的数据存储(如关系数据库、数据湖、云存储、边缘设备等)之上构建了一个抽象层。通过连接器、API和标准化协议,它能够无缝集成结构化、半结构化和非结构化数据,为用户和应用提供统一的查询接口,无需关心数据的具体位置和格式。
2. 智能的元数据驱动管理
数据编织的核心是主动元数据。它不仅被动地描述数据(如模式、位置),还通过持续收集数据使用情况、血缘关系、业务术语、数据质量指标等信息,形成丰富的上下文。结合AI/ML技术,系统可以自动推荐相关数据集、检测数据异常、优化查询性能,甚至预测存储需求,实现数据管理的自动化与智能化。
3. 增强的数据治理与安全
通过全局的数据血缘和策略引擎,数据编织能够实施一致的数据治理策略(如隐私合规、访问控制、生命周期管理)。无论数据在何处移动或处理,策略都能自动附着和执行,确保数据安全与合规,同时提供透明的审计跟踪。
4. 灵活、可扩展的架构支持
数据编织采用分布式、微服务化的架构,支持混合云和多云环境。这使得数据处理和存储服务可以根据业务需求动态扩展,实现成本优化和性能提升。例如,热数据可以存放在高性能存储中,而冷数据自动归档到成本更低的存储层。
三、数据编织的关键技术组件
- 知识图谱:将元数据、业务术语和数据资产之间的关系以图的形式建模,提供强大的语义搜索和关联发现能力。
- AI与机器学习:用于元数据丰富、自动化分类、异常检测、优化建议等。
- 数据虚拟化:实现数据的逻辑整合,避免不必要的数据移动和复制。
- 自动化编排与运维:自动化执行数据集成、质量检查、策略实施等任务。
四、应用价值与未来展望
数据编织为企业带来的核心价值在于:
- 提升数据发现与使用效率:业务用户能更快地找到可信数据,加速分析洞察。
- 降低集成与管理成本:减少手动编码和重复工作,简化数据架构。
- 增强业务敏捷性:快速响应新的数据需求,支持创新应用。
- 保障数据可信与合规:建立端到端的可观测性与控制力。
随着企业数字化转型的深入,数据编织正从概念走向落地。它不仅是技术架构的演进,更是向以数据为中心、智能驱动的运营模式的转变。结合边缘计算、实时流处理等趋势,数据编织有望成为企业数据基础设施的“中枢神经系统”,为无处不在的数据处理与存储需求提供无缝、智能的支持服务。
###
总而言之,数据编织代表了数据管理范式的一次重要飞跃。它通过智能、自适应的方式连接分散的数据孤岛,为企业构建了一个灵活、可靠且高效的数据支持层。对于任何希望充分释放数据潜力、驱动数字化转型的组织而言,理解和投资数据编织架构,将是构建未来竞争力的关键一步。