在软件系统类的创新创业竞赛、新苗人才计划、国家级大学生创新创业训练计划(国创/大创)等项目中,一份逻辑清晰、技术详实、前瞻可行的《技术方案》是项目计划书或申报书的核心骨架与灵魂。它不仅是评审专家评估项目技术含量、创新性与可行性的关键依据,更是团队自身厘清技术路线、规避开发风险、规划资源投入的行动蓝图。本文旨在提供一个约五千字的系统性与建议,聚焦于如何撰写技术方案中至关重要的“数据处理与存储支持服务”部分,助力项目脱颖而出。
一、 技术方案的整体定位与结构框架
在动笔之前,须明确技术方案在整体文档中的角色:它是对“做什么”和“怎么做”的技术性深度阐释,需与项目概述、市场分析、商业模式等部分紧密呼应,共同证明项目的价值与可实现性。
一个完整的技术方案通常包含以下模块:
- 系统架构设计:包括总体架构图(如分层架构、微服务架构)、技术选型说明。
- 核心功能模块详述:分解系统功能,说明各模块的技术实现思路。
- 数据处理与存储方案(本文核心):详细阐述数据从产生到消亡的全生命周期管理策略。
- 关键技术与创新点:突出项目的技术壁垒与独创性。
- 系统性能、安全与可靠性设计:定义非功能性指标及保障措施。
- 开发计划与技术风险:划分开发阶段、预估技术难点与应对策略。
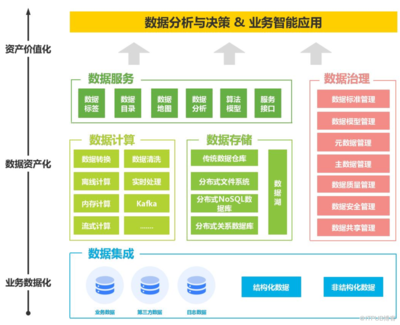
二、 数据处理与存储支持服务方案详解
这是技术方案中最能体现项目技术深度和严谨性的部分。对于数据驱动的软件系统(如大数据分析平台、物联网应用、社交网络、电商系统等)尤为重要。撰写时应遵循“数据流”与“生命周期”两条主线。
第一部分:数据处理流程设计
- 数据源分析:
- 类型:明确数据来源(如用户操作日志、传感器实时流、第三方API、数据库快照、上传的文件等)。
- 格式与频率:描述数据格式(JSON、CSV、二进制流等)、数据生成频率(持续流、定时批量)、数据量级预估(日增/月增数据量)。
- 示例(竞赛项目中):“本项目移动端App每日产生约10万条用户行为事件日志(JSON格式),同时每小时从公开气象API接口获取一次城市天气数据。”
- 数据采集与接入:
- 技术选型与理由:根据数据源特性选择工具。如实时流采用Apache Kafka、Flink;日志采集用Logstash、Filebeat;批量导入用Sqoop、DataX。对于轻量级竞赛项目,可选用云服务商提供的托管服务(如AWS Kinesis、阿里云DataHub)或开源中间件,并说明选型理由(如社区活跃、与后续组件兼容、学习成本低)。
- 数据缓冲:说明如何应对数据洪峰,保障系统稳定性。
- 数据预处理与清洗:
- 清洗规则:定义如何处理缺失值、异常值、重复数据、格式不一致等问题。
- 转换与标准化:说明数据归一化、编码转换(如one-hot编码)、时间戳标准化等步骤。
- 实现方式:可采用ETL工具(如Apache NiFi)、编写Spark/Python清洗脚本,或在流处理框架中定义清洗算子。
- 数据计算与分析:
- 批处理与流处理:根据业务需求划分。批处理用于T+1报表、历史数据挖掘;流处理用于实时监控、实时推荐。
- 计算框架:批处理可选Spark、Hive;流处理可选Flink、Spark Streaming;实时查询可选ClickHouse、Druid。结合项目规模和团队技术栈,选择最合适的框架。
- 算法模型集成:如果涉及机器学习,需说明训练数据如何准备、模型如何上线服务(在线预测API)。
第二部分:数据存储架构设计
- 存储选型策略(核心):根据数据的使用场景(在线事务、离线分析、缓存、搜索)选择合适的存储系统,遵循“Right Tool for the Right Job”原则。
- 结构化数据(关系型数据库):如MySQL、PostgreSQL。用于存储用户账户、订单交易等需要强一致性、事务支持的核心业务数据。需说明表结构设计要点(范式考量、索引策略)。
- 非结构化/半结构化数据(NoSQL):
- 文档型(如MongoDB):存储JSON格式的用户画像、商品详情。
- 键值型(如Redis):用作高速缓存(会话缓存、热点数据)、排行榜。
- 列式存储(如HBase、Cassandra):适用于海量数据、高并发随机读写的场景(如用户行为日志查询)。
- 时序数据库(如InfluxDB、TDengine):专为带时间戳的监控指标、传感器数据设计,高效压缩,查询快。
- 数据仓库:如Apache Hive、StarRocks、Snowflake(云上)。用于整合多源数据,支持复杂的OLAP分析。需简要描述维度建模思想(星型/雪花模型)。
- 对象存储:如AWS S3、阿里云OSS、MinIO(自建)。用于存储图片、视频、文档等静态大文件,成本低、扩展性强。
- 数据分层设计(数据湖/仓库架构):
- 提出将原始数据、清洗后数据、轻度汇总数据、高度聚合/应用数据分层存储的理念(如ODS->DWD->DWS->ADS)。这体现了对数据治理的深入思考,极具专业性。
- 说明各层的数据格式、存储介质(HDFS、对象存储)、保留策略及访问权限。
- 数据备份、容灾与归档方案:
- 备份策略:定期全量备份+增量备份的频率与方式。
- 容灾:考虑同城异地备份,或利用云数据库的多可用区部署。
- 冷热数据分离:定义将不常访问的历史数据迁移至更低成本存储(如从HDFS至对象存储)的策略。
第三部分:数据服务与API设计
数据处理和存储的最终目的是提供服务。需规划如何将数据能力暴露给前端或其他系统。
- 数据服务层:设计统一的RESTful API或GraphQL接口,对外提供数据查询、写入服务。
- 数据可视化支持:说明如何为管理后台或报表系统提供数据接口,可提及集成开源BI工具(如Superset、Metabase)或自研图表组件。
- 实时数据推送:如需实时仪表盘或通知,说明使用WebSocket或Server-Sent Events (SSE)技术。
三、 撰写要点与提升技巧
- 图文并茂,架构图至关重要:绘制清晰的数据流向图(Data Flow Diagram)和数据存储分层架构图。使用标准的图形符号(如UML),让专家一目了然。
- 紧扣“创新”与“可行性”:技术选型不必盲目追求最新最炫,但要合理。对于学生项目,优先选择主流、有丰富学习资源、社区支持好的技术。在某个环节(如使用一种新型时序数据库优化查询效率,或设计一种独特的流处理算法)体现创新性思考。
- 量化指标:尽可能给出量化预估,如“预计系统上线初期存储容量需求为500GB,随着用户增长,年数据增量约2TB”,“要求核心API接口响应时间P95 < 200ms”。
- 考虑竞赛/申报特点:
- 完整性:即使项目初期不实现所有高级特性(如复杂的容灾),也应在方案中体现未来演进的可能。
- 成本意识:提及将利用云服务的免费额度、校园优惠,或使用开源软件降低成本和运维难度。
- 团队能力匹配:说明团队成员已具备或计划学习相关技术,证明方案的执行有保障。
- 关联业务场景:始终将技术方案与项目要解决的实际业务问题挂钩。例如,“为解决用户行为分析的实时性需求,我们引入了Flink流处理框架,使得推荐模型能基于最近10分钟的用户点击行为进行实时更新。”
四、 常见误区与规避
- 误区一:堆砌技术名词,逻辑混乱。→ 规避:以数据流为主线,讲好“数据故事”。
- 误区二:存储方案单一,一把梭用MySQL。→ 规避:深入分析数据多样性,采用混合持久化策略。
- 误区三:忽视数据安全与隐私。→ 规避:增加章节说明数据脱敏、加密传输存储、访问权限控制(RBAC)的设计。
- 误区四:方案脱离实际,无法落地。→ 规避:进行技术预研,评估学习成本和开发周期,制定分阶段实施计划。
###
撰写一份出色的数据处理与存储技术方案,需要将系统的业务需求翻译成精准的技术语言,并在先进性与可行性、完整性与聚焦性之间取得平衡。它不仅是通向竞赛奖项或项目资助的敲门砖,更是团队在项目开发前进行的一次至关重要的“沙盘推演”。投入时间精心打磨此部分内容,必将为整个项目的成功奠定坚实的技术基石。希望本指南能为您的软件系统创新创业之旅提供清晰的指引。